Mining Hamlet
A lot of Shakespeare’s tragic heores don’t dominate the first act of their plays. Instead, other characters speak about them, setting the scene for exploring their personalities as the play unfolds. This is the case of Julius Caesar, Macbeth and Othello (but not of King Lear).
In this post I go over the text of Hamlet, Prince of Denmark, using the quantity of lines spoken by character to visualize the dynamic of the play. We’ll get the chance to use dplyr and some regular expressions.
Getting the text of the plays
The text of Shakespeare’s plays is available from the gutenberg package. I downloaded the text and made it available as a data frame here
so you don’t have to.
books <- readRDS('shakespeare_plays.rds')
hamlet <- books %>%
filter(title == "Hamlet, Prince of Denmark")Extracting the Character names
We can use a regular expressions to extract character names from the lines of the play. Most characters names appear abreviated (Ham. for Hamlet, Hor. for Horatio).
lag and cumsum are useful inside call to mutate to look at consecutive lines in the data frame. I also create a line number index with row_number.
# Fran., Ham., Pol.
CHAR_REGEX <- regex("^([A-Z][a-z]*)\\.")
# Stage Dir
# [Enter Horatio and Marcellus.]
STAGEDIR_REGEX <- regex("(\\[.+\\])")
hamlet <- hamlet %>%
mutate(char_name = str_match(text, CHAR_REGEX)[,2]) %>%
mutate(stage_dir = str_match(text, STAGEDIR_REGEX)[,2],
char_name = if_else(!is.na(stage_dir), "director", char_name)) %>%
mutate(start_speech = !is.na(char_name) &
lag(text) == "") %>%
mutate(speech_idx = cumsum(start_speech)) %>%
mutate(line = row_number()) %>%
select(text, char_name, start_speech, speech_idx, line)Now we need to create a data frame of speeches. Each line is a speech in the play, with the character that speaks it and the number of lines it lasts.
# Build a df with speech, start line, length char
speeches_df <- hamlet %>%
group_by(speech_idx) %>%
summarise(char_name = first(char_name),
line = first(line),
speech_length = as.integer(n()-2)) %>%
dplyr::filter(char_name != "director")The longest speech is by Hamlet (duh!), and starts at line 2677.
speeches_df %>%
arrange(-speech_length)
## # A tibble: 1,077 x 4
## speech_idx char_name line speech_length
## <int> <chr> <int> <int>
## 1 498 Ham 2677 60
## 2 234 Ghost 1296 50
## 3 69 King 383 39
## 4 761 Ham 4039 36
## 5 154 Laer 846 35
## 6 522 Ham 2857 35
## 7 480 Pol 2553 34
## 8 479 Ham 2518 33
## 9 568 Ham 3139 32
## 10 84 King 502 31
## # ... with 1,067 more rowsLets take a look at the text of the speech:
hamlet %>%
filter(line %in% 2677:2690) %>%
select(text)
## # A tibble: 14 x 1
## text
## <chr>
## 1 Ham.
## 2 Ay, so, God b' wi' ye!
## 3 Now I am alone.
## 4 O, what a rogue and peasant slave am I!
## 5 Is it not monstrous that this player here,
## 6 But in a fiction, in a dream of passion,
## 7 Could force his soul so to his own conceit
## 8 That from her working all his visage wan'd;
## 9 Tears in his eyes, distraction in's aspect,
## 10 A broken voice, and his whole function suiting
## 11 With forms to his conceit? And all for nothing!
## 12 For Hecuba?
## 13 What's Hecuba to him, or he to Hecuba,
## 14 That he should weep for her? What would he do,Lets focus on the characters with the most lines:
top_speakers <- speeches_df %>%
group_by(char_name) %>%
summarize(total_lines = sum(speech_length)) %>%
arrange(-total_lines) %>%
head(6)Use inner_join to discard the less important characters:
# Keep speeches by these speakers
speeches_df_main <- speeches_df %>%
inner_join(top_speakers, by = "char_name") %>%
filter(!is.na(char_name))The last thing we need is a column with the cumulative lines spoken by each character:
speeches_df_main <- speeches_df_main %>%
group_by(char_name) %>%
mutate(cum_lines = as.integer(cumsum(speech_length))) %>%
ungroup() %>%
mutate(char_name = fct_recode(char_name,
"Horatio" = "Hor",
"King Claudius" = "King",
"Laertes" = "Laer",
"Polonius" = "Pol",
"Ophelia" = "Oph",
"Hamlet" = "Ham"))Now we can plot the play:
# color palette
col.pal <- RColorBrewer::brewer.pal(8, "Set2")
# Plot Play
g <- ggplot(speeches_df_main, aes(line, cum_lines, fill = char_name)) +
guides(colour = guide_legend(title = NULL)) +
geom_area(alpha = 0.8) +
guides(fill = guide_legend(title = NULL)) +
scale_fill_brewer(palette = "Set2") +
labs(title = "Cumulative lines", subtitle = "By Character") +
xlab("Line") +
ylab("Spoken Lines") +
theme_bw() +
theme(plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
panel.border = element_blank()) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
facet_wrap(~char_name) +
guides(fill="none")
g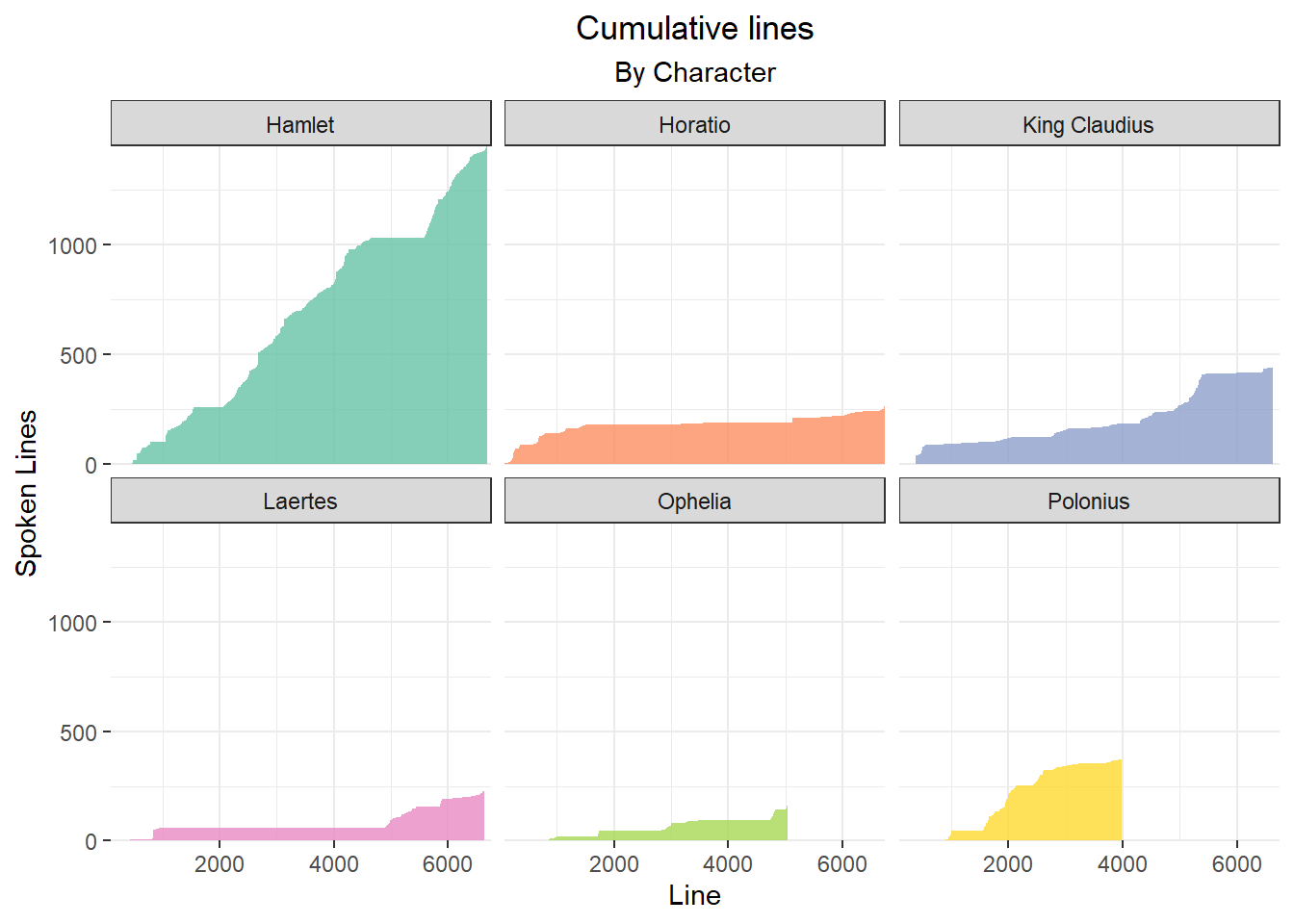
The plot shows the dynamic of the play quite nicely. Horatio, Hamlet’s friend figures quite prominenty at the beggining. Polonius has a lot of lines in the middle of the play, until he’s caught behind the arras just before line 4000. Ophelia dies around line 5000.
Towards the end, Hamlet eats up the whole play in his showdown with King Claudius.