Tidy Vargas Llosa
Mario Vargas Llosa es uno de mis novelistas preferidos. El año pasado releí varios de sus libros y escribí algunos reviews. En este post aplico algunas de las técnicas de este libro a las novelas.
Datos
Para este proyecto, conseguí todas las novelas de Vargas Llosa en Inglés en formato digital (epub, mobi) y las convertí a texto.
El primer paso para analizar texto es estructurarlo para el análisis. Este proceso se llama tokenización, porque implica separar el texto en “tokens”, pequeñas unidades de análisis. En este caso vamos a trabajar con texto tokenizado en palabras. El proceso de tokenización también puede incluír convertir las palabras a minúsculas y sacar las puntuaciones.
Wordcloud
El análisis más básico de texto on R se llama WordCloud, y grafica las palabras más usadas en el texto analizando con el tamaño de la fuente proporcional a la frecuencia en que aparecen los términos.
Para hacer un WordCloud para una novela concreta, filtramos el data frame para que tenga solo el texto de la novela, y usamos anti_join para sacar las stop words. Las stop words son palabras como “la” y “de”. Suelen ser las palabras más usadas, pero no tienen información sobre el contenido del texto, por lo que es conveniente sacarlas.
Los otros tokens que llaman la atención en este análisis son los nombres de los personajes. Rigoberto y Lucrecia son los tokens más usados en Los cuadernos de don Rigoberto.
s <- mvll_tidy %>%
filter(title == "Notebooks of Don Rigoberto" ) %>%
filter(!str_detect(word, "\u2019")) %>% # remove didn't, they're, etc.
anti_join(stop_words) %>%
count(word, sort = TRUE) %>%
with(wordcloud(word, n, max.words = 40))
Palabras características de cada libro
Otro análisis similar es el índice de tf-idf. Esta métrica busca extraer los términos más característicos de un texto.
book_words <- mvll_tidy %>%
count(title, word, sort = TRUE) %>%
ungroup %>%
bind_tf_idf(word, title, n)
plt <- book_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word))))
plt %>%
filter(title %in% libros$title[10:13]) %>%
group_by(title) %>%
top_n(10) %>%
ungroup %>%
ggplot(aes(word, tf_idf, fill = title)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~title, ncol = 2, scales="free") +
coord_flip()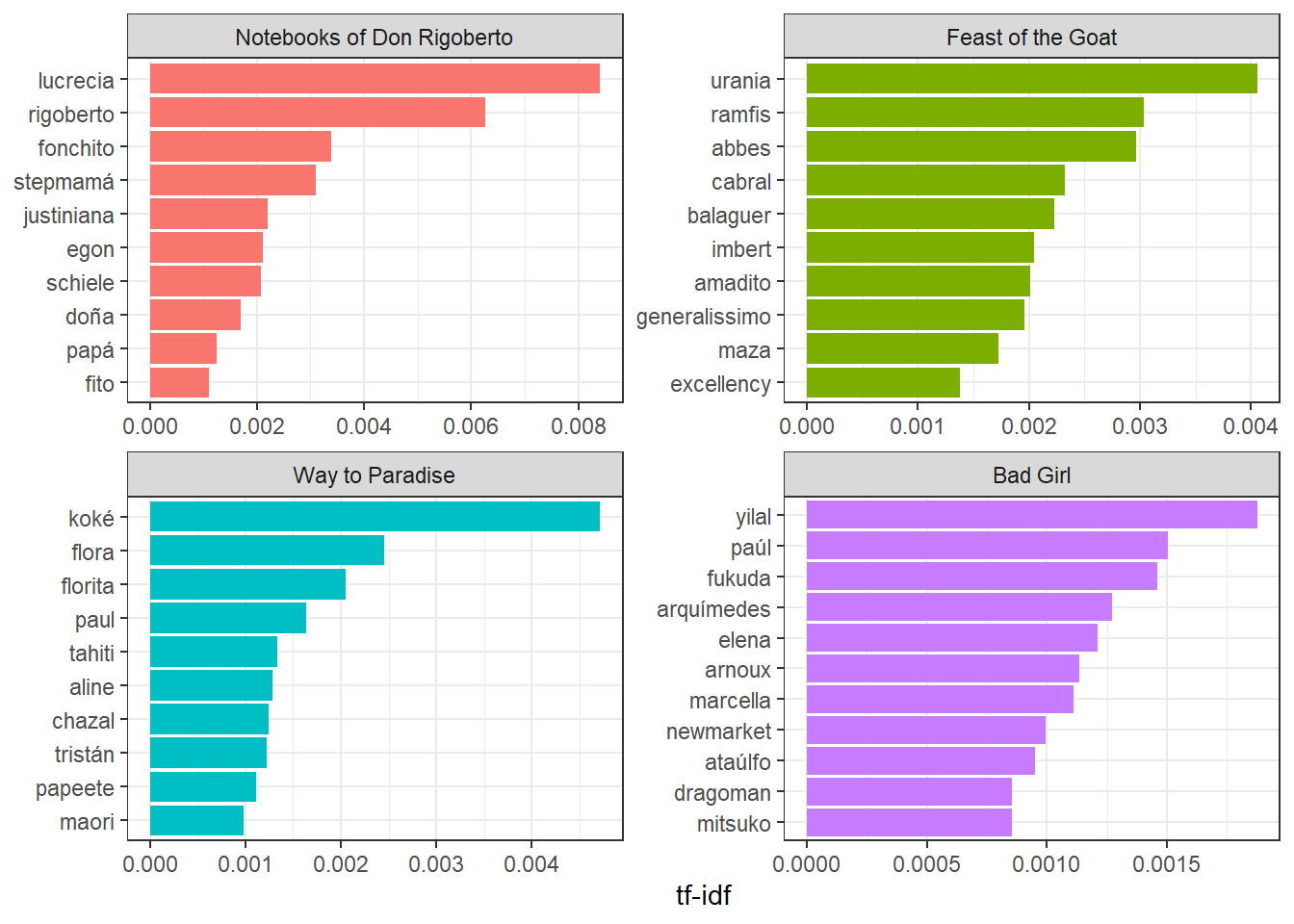
Sentiment Analysis
El análisis de sentimiento busca crear métricas para que tan positivo o negativo es el texto que estamos analizando. Para eso, necesitamos un “léxico”, una base de datos con palabras y sus sentimientos correspondientes. Bing es uno de los léxicos disponibles, y para cada palabra define si es positivo o negativo:
head(get_sentiments("bing"))## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 2-faces negative
## 2 abnormal negative
## 3 abolish negative
## 4 abominable negative
## 5 abominably negative
## 6 abominate negative
Para analizar el texto de las novelas, usamos el léxico para determinar si cada palabra es positiva o negativa. Después tomamos unidades de 80 líneas y calculamos sentiment como la diferencia entre la cantidad de palabras positivas y negativas. Esto nos da una métrica de que tan positivas son las palabras usadas en esa parte del texto.
La columna idx son bloques de 80 líneas y sirven para encontrar pasajes en las novelas después de visualizarlas.
mvll_sentiment <- mvll_tidy %>%
filter(title %in% c("Aunt Julia and the Scriptwriter",
"Conversation in the Cathedral",
"A Fish in the Water",
"Feast of the Goat",
"Notebooks of Don Rigoberto",
"Bad Girl")) %>%
inner_join(get_sentiments("bing")) %>%
count(title, index = line %/% 80, sentiment) %>%
spread(sentiment, n) %>%
mutate(sentiment = positive - negative)
ggplot(mvll_sentiment, aes(index, sentiment, fill=title)) +
geom_col() +
facet_wrap(~title, ncol = 2, scales = "free_x") +
guides(fill=FALSE)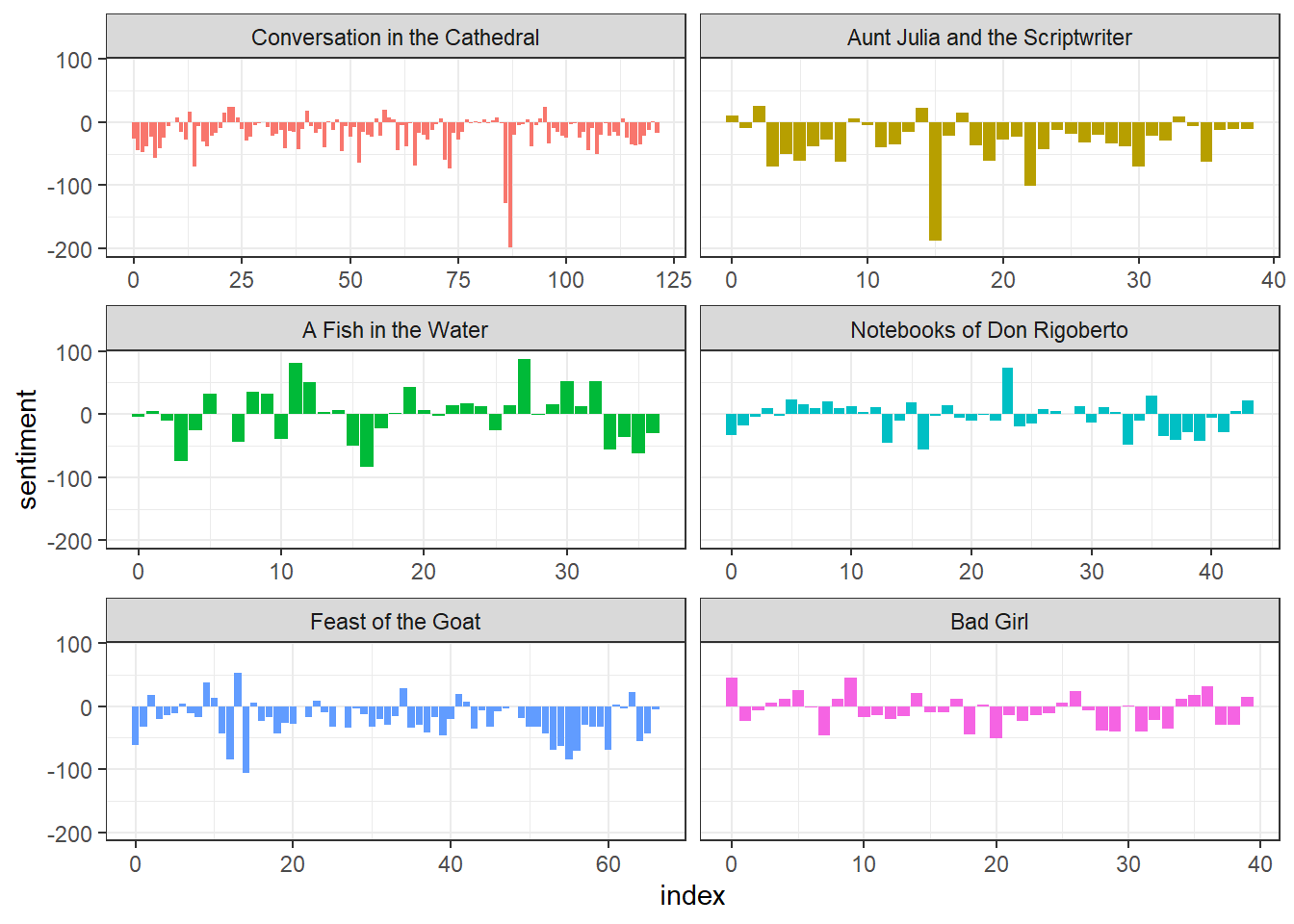
En general, Vargas Llosa usa pocas palabras con sentimientos positivos. Esta visualización también identifica momentos particularmente buenos o malos en las novelas: en la mitad de los Cuadernos de don Rigoberto hay una parte que destaca como buena.