Personas y lugares en las novelas de Mario Vargas Llosa
spacyR es una interfaz para usar una librería de NLP de python -spacy- desde R. En este post exploro un poco como detectar nombres de personas y de lugares usando esta librería para analizar cuáles son los personajes principales y los lugares más mencionados en cada capítulo de Las Travesuras de la Niña Mala.
Corpus
A partir del texto de las novelas (en inglés), creo un data frame con una línea por fila y columnas con el texto y el capítulo al que corresponde cada línea.
bad_girl_url <- "https://raw.githubusercontent.com/rlabuonora/mvll_nlp/master/txt/bad_girl.txt"
bad_girl_raw <- readLines(bad_girl_url, encoding = "UTF-8")
bad_girl_lines <- tibble(text = bad_girl_raw) %>%
mutate(chapter = str_detect(text, "\\d{1,2}.?$"), # Detect 1, 2, 3 ..7
chapter = cumsum(chapter)) %>% # cumsum o fill
tibble::rowid_to_column(var="doc_id")Spacy
Una vez que importé el texto de la novela, uso spacy_parse para detectar las named entities. Una named entity es una entidad que aparece mencionada en el texto.
Spacy usa un algoritmo para detectar cuáles tokens en el texto pertenecen a una entidad y de que tipo de entidad se trata.
bad_girl_parsed <- spacy_parse(bad_girl_lines$text, lemma = FALSE, entity = TRUE, nounphrase = TRUE)
ents <- entity_extract(bad_girl_parsed, type = "all") %>%
mutate(doc_id = as.numeric(str_extract(doc_id, "\\d{1,4}"))) %>%
left_join(select(bad_girl_lines, chapter, doc_id))
head(ents)## doc_id sentence_id entity entity_type chapter
## 1 1 1 1 CARDINAL 1
## 2 10 1 a_fabulous_summer DATE 1
## 3 10 2 Pérez_Prado PERSON 1
## 4 10 2 twelve CARDINAL 1
## 5 10 2 Carnival PERSON 1
## 6 10 2 the_Lawn_Tennis_of_Lima PRODUCT 1El data frame ents tiene un doc_id que nos permite vincular estos resultados con el input original (donde tenemos a què capítulo pertence cada frase, el nombre de la entidad detectada, y el tipo de entidad detectada.)
Visualización
Para la visualizión del resultado, veamos cuáles son las entidades de tipo persona y lugar más nombradas en cada capítulo:
personas_por_capitulo <- ents %>%
filter(entity_type == "PERSON") %>%
filter(!entity %in% c("’s")) %>% # sacar entidades mal clasificadas
group_by(chapter, entity) %>%
summarize(mentions = n()) %>%
arrange(chapter, -mentions) %>%
top_n(5, mentions) # Los 5 personajes más mencionados
personas_por_capitulo %>%
ggplot(aes(entity, mentions, fill = entity)) +
geom_col() +
coord_flip() +
facet_wrap(~chapter, scales="free_y") +
guides(fill=FALSE) +
labs(y="Menciones", x="Personajes",
title = "Travesuras de la Niña Mala",
subtitle="Personajes más mencionados por capítulo")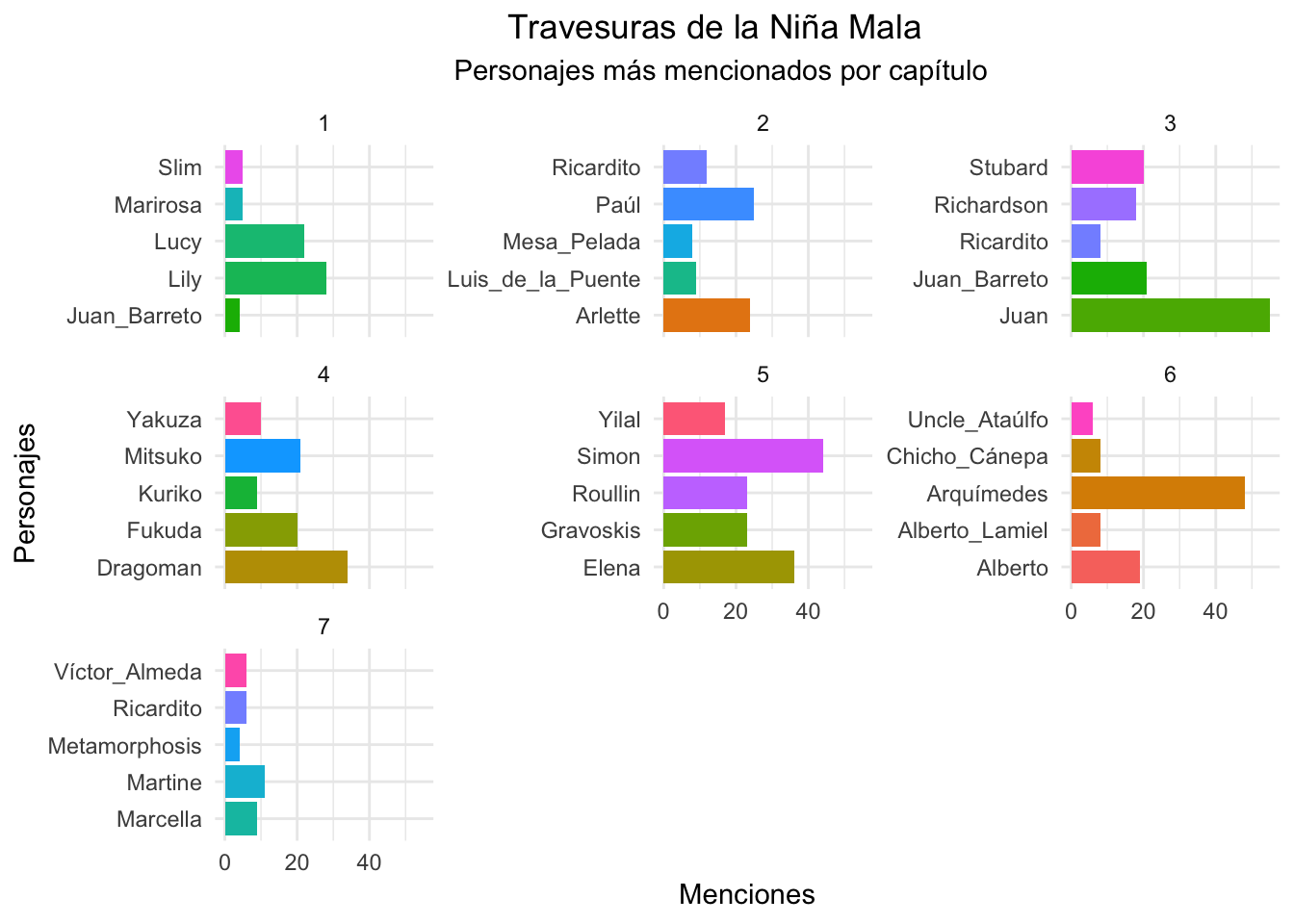
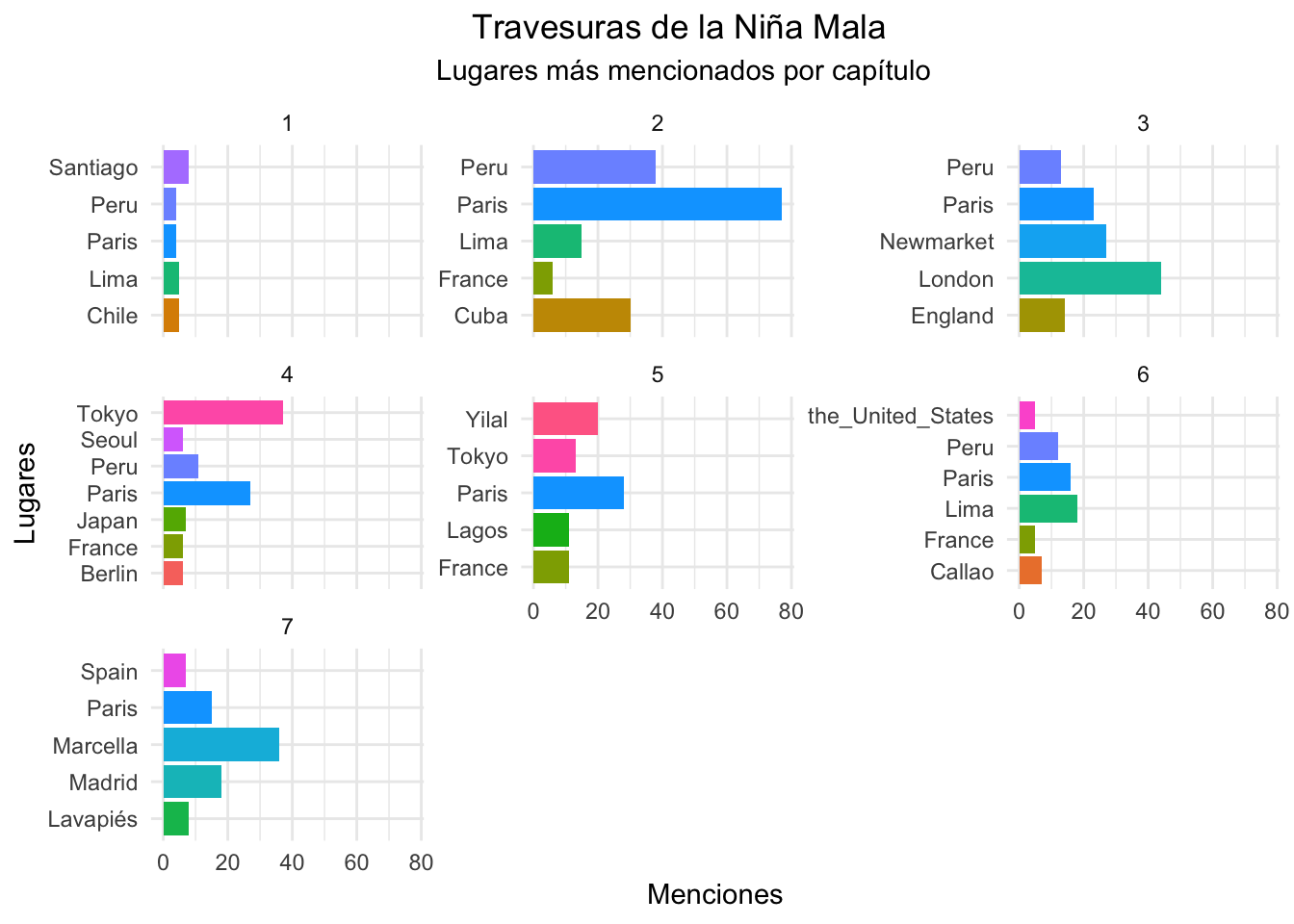
Ahora hacemos lo mismo pero nos quedamos con las entidades de tipo GPE: (Geopolitical Entity).
lugares_por_capitulo <- ents %>%
filter(entity_type == "GPE") %>% # GPE => Geopolitical Entity
filter(!entity %in% c("Salomón", "Alberta", "’s",
"Mitsuko", "Elena")) %>% # Sacar ents mal clasificadas
group_by(chapter, entity) %>%
summarize(mentions = n()) %>%
arrange(chapter, -mentions) %>%
top_n(5, mentions)
lugares_por_capitulo %>%
ggplot(aes(entity, mentions, fill = entity)) +
geom_col() +
coord_flip() +
facet_wrap(~chapter, scales="free_y") +
guides(fill=FALSE) +
labs(y="Menciones", x="Lugares",
title = "Travesuras de la Niña Mala",
subtitle="Lugares más mencionados por capítulo")